

We’ve reached a point where the question is no longer if AI can transform business, but how to harness it effectively. Leaders across various industries are leveraging AI to streamline operations, expedite decision-making, and deliver personalized experiences. Yet over 80% of enterprise AI initiatives struggle to scale beyond pilots, not because the technology fails, but because the data feeding these systems isn’t ready for AI.
Most know that data powers AI, but few realize that raw, unstructured data cannot be consumed directly. For AI to deliver reliable insights, data must be structured, cleaned, and precisely labeled. Data labeling translates raw information into a language AI understands; without it, patterns are misread, predictions falter, and opportunities slip away.
High-quality labeled data is the bridge between ambition and results. It ensures AI interprets context, identifies meaningful patterns, and produces insights leaders can trust. In predictive analytics, for example, mislabeled data can cause AI to misidentify high-value customers or operational bottlenecks, leading to wasted resources. Well-prepared data, on the other hand, empowers confident action and turns information into intelligence that drives measurable impact.
By prioritizing data quality and labeling from the start, organizations safeguard AI accuracy while unlocking its potential to accelerate strategy, optimize operations, and fuel innovation. This transforms AI from a promising tool into a strategic engine for outcomes that last.
What is data labeling
Data labeling is the process of assigning meaning, context, and structure to raw data, enabling AI and machine learning models to understand and act upon it. Think of it as translating your business information into a language your AI can interpret reliably. Without this step, even the most advanced models cannot recognize patterns, make accurate predictions, or deliver actionable insights.
The types of data that can be labeled are diverse, reflecting the wide range of information businesses generate. Text can be tagged for sentiment, intent, or entities. Images and video can be annotated for objects, scenes, or activities. Audio can be labeled for speech, tone, or key events. Sensor and operational data can be structured to represent metrics, anomalies, or system behavior. Each properly labeled data point becomes a building block that trains your AI to understand the real-world nuances of your business.
The outcome of effective data labeling is clarity and actionable intelligence. It transforms unstructured, raw information into structured datasets that your AI can learn from efficiently. This ensures consistent results, reduces errors, and strengthens the reliability of insights that drive strategic decisions.
From an executive perspective, data labeling is a strategic enabler. Your choices in accuracy, consistency, and completeness determine whether AI delivers real business impact or underperforms.
In essence, effectively labeled data transforms raw information into a foundation that accelerates decisions, optimizes operations, and drives meaningful outcomes.
Why data labeling is essential for businesses
How you prepare your data today directly determines how effectively your AI and machine learning models perform tomorrow. Data labeling transforms raw, unstructured information into high-quality, structured datasets that AI can interpret reliably and accurately. Accurate labeling creates clarity from complexity, enabling faster decision-making, reducing operational risks, and generating measurable business outcomes. For organizations aiming to scale AI successfully, investing in high-quality labeled data is no longer optional; it is a strategic imperative.
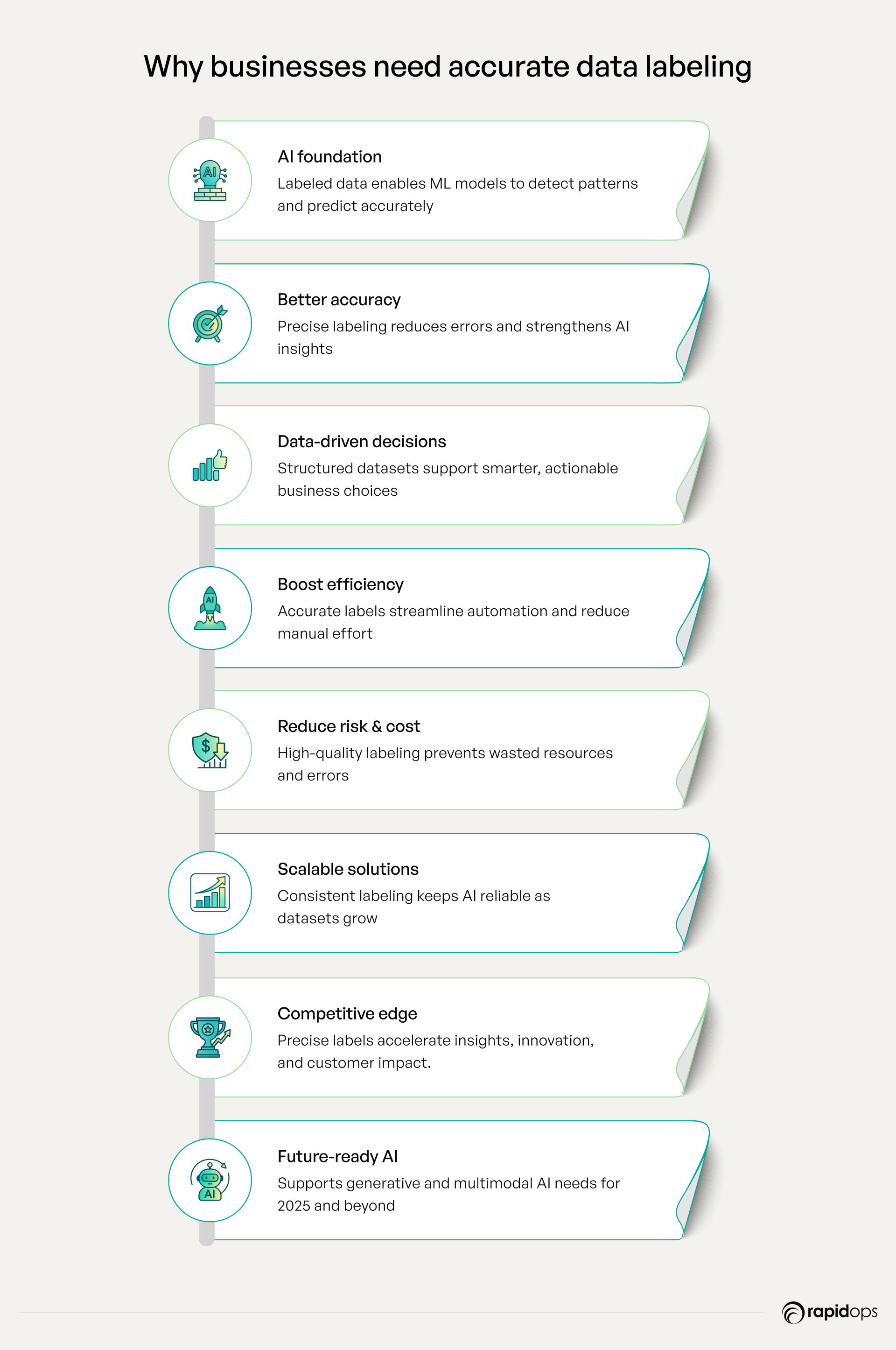
Foundation for AI and machine learning
High-quality labeled data provides context that allows ML models to recognize patterns, interpret relationships, and produce dependable predictions. It establishes the foundation that ensures AI initiatives translate into real-world business impact, whether for natural language processing (NLP), computer vision, or predictive analytics. Without structured labeling, even advanced deep learning models struggle to deliver reliable insights.
Improves model performance and accuracy
The accuracy and consistency of data labeling directly determine how well AI interprets information. Proper annotation, including bounding boxes, segmentation, and entity tagging, reduces errors, strengthens predictions, and ensures that insights are actionable and trustworthy for strategic decision-making. High-quality labeled datasets improve model training, making AI outputs more reliable across real-world applications.
Drives data-driven decisions
Labeled datasets convert raw information into intelligence that leaders can trust. Structured training data supports optimized operations, informed strategies, and personalized customer experiences, aligning AI outputs with business objectives. Executives can leverage these insights to make proactive, confident decisions that drive measurable outcomes.
Enhances automation and efficiency
AI-powered automation relies on accurately labeled data to function effectively. Structured datasets ensure scalable processes, reduce manual intervention, and allow teams to focus on high-value initiatives rather than repetitive labeling tasks. This makes AI applications more efficient, consistent, and reliable.
Reduces risk and cost
Inconsistent or inaccurate data labeling can misguide ML models, resulting in wasted resources, operational inefficiencies, and poor outcomes. By ensuring high-quality labeling, businesses can mitigate these risks, safeguard their investments in AI infrastructure, and enhance operational resilience.
Supports scalability
As AI adoption expands across departments and geographies, consistent data labeling practices ensure models remain reliable and effective for enterprise-wide deployment. Scalable labeling strategies, whether using human annotators, programmatic approaches, or automated data labeling tools, maintain quality while handling growing datasets.
Gives a competitive advantage
Organizations that invest in precise data labeling gain faster, more accurate insights. This empowers proactive decision-making, improved customer engagement, and accelerated innovation cycles across computer vision, NLP, and other AI applications.
Aligns with 2025 AI demands
Next-generation AI systems, including generative AI and multimodal models, require diverse, high-quality labeled datasets. Effective data labeling prepares businesses to meet evolving AI needs, ensuring competitiveness, future readiness, and the ability to extract maximum value from AI-driven strategies.
Types of data labeling
Data labeling is not a one-size-fits-all activity; the type of data determines the labeling approach, which directly impacts the accuracy, scalability, and effectiveness of your AI and machine learning models. Understanding the various types of labeling ensures you choose the right strategy, tools, and resources, enabling your AI initiatives to deliver high-quality, actionable insights.
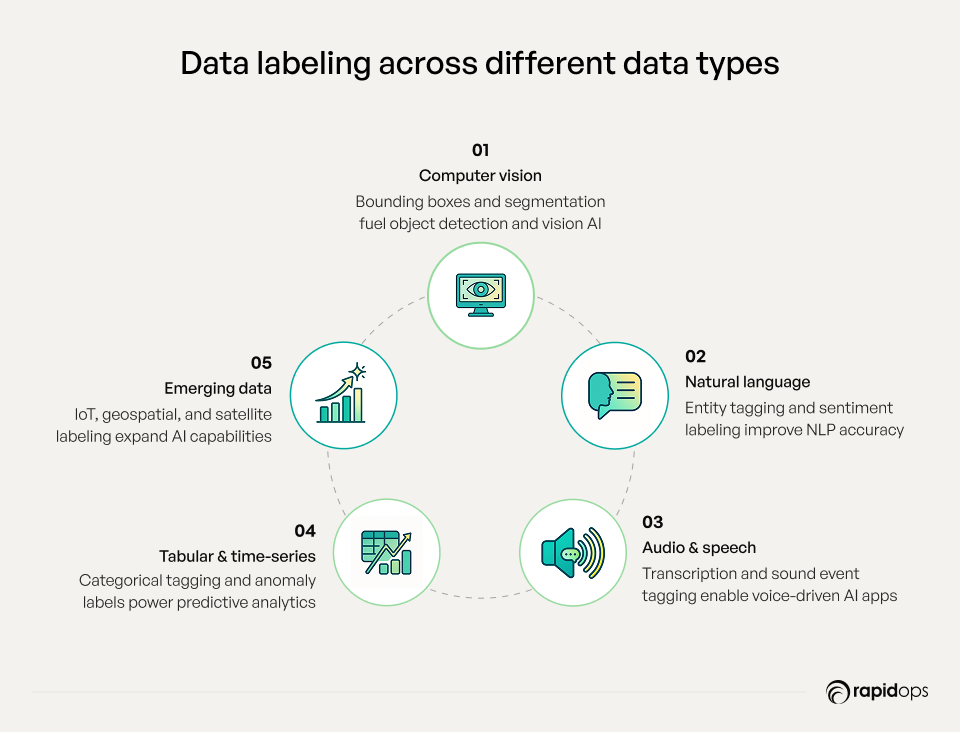
Computer vision
Visual data requires specialized labeling for machine learning and deep learning models. Techniques include annotating images with bounding boxes, segmentation masks, object classification, marking key points or landmarks, labeling video frames sequentially, tracking objects across frames, and recognizing specific actions. Accurate computer vision labeling enables AI models to detect patterns, identify objects, and interpret real-world scenarios, thereby powering applications such as object detection, image recognition, and visual search.
Natural language processing (NLP)
Text-based data demands contextual understanding for effective NLP model training. Common labeling methods include sentiment analysis, entity tagging, intent classification, and text categorization. High-quality labeled text data enables AI models to comprehend language nuances, extract meaning from unstructured information, and support predictive analytics, chatbots, and virtual assistants, improving customer engagement and content understanding.
Audio and speech
Audio labeling involves transcription, sound event annotation, speaker identification, and audio classification. Structured audio data labeling allows AI to process speech and sound accurately, powering voice assistants, call center automation, real-time audio recognition, and other machine learning applications.
Tabular and time-series data
Structured datasets, including operational, financial, or sensor-driven data, benefit from categorical labeling, anomaly tagging, and time-series structuring. Correct labeling ensures models can identify trends, detect deviations, and generate predictive analytics, providing actionable insights for decision-making and operational optimization.
Other and emerging data types
As AI evolves, new forms of data require attention, including IoT and sensor data, geospatial information, satellite imagery, and specialized streams. Labeling in these areas unlocks advanced AI capabilities for predictive maintenance, environmental monitoring, and location-based intelligence, expanding the scope of high-quality training data across industries.
By understanding the unique labeling requirements of each data type, organizations can apply precise methods that enhance data quality, ensure consistent machine learning model performance, and make every dataset a reliable foundation for accurate and effective AI training.
How does data labeling work
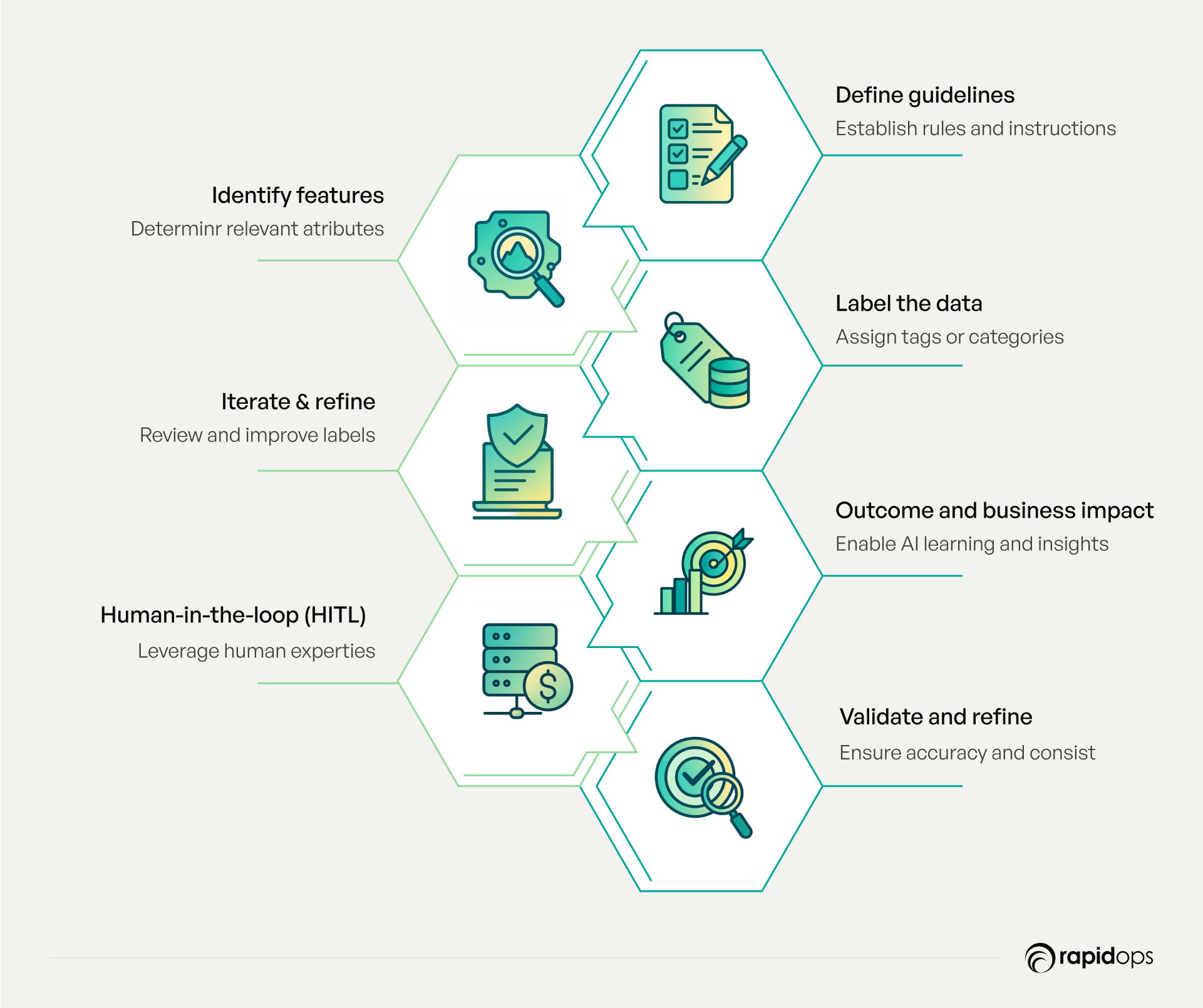
Data labeling is the process of transforming raw, unstructured data into high-quality data that AI and machine learning models can understand and act upon. It is not merely a technical task; it is a strategic capability that directly impacts model accuracy, reliability, and the business value of your AI initiatives.
The data labeling process begins with defining clear annotation standards and labeling guidelines. These guidelines ensure consistency, relevance, and context across all labeling tasks, providing a foundation for high-quality data. Next, features within the data are identified and precisely labeled using labeling tools or labeling teams, assigning tags that enable AI to interpret and learn from the information.
Each labeled dataset undergoes validation and quality checks, ensuring high-quality data standards are maintained as datasets scale. Iteration is crucial, and continuous refinement ensures that data labeling work evolves alongside changing real-world business needs and AI models.
Data labeling can be executed through multiple approaches: fully manual annotation by experts, semi-automated workflows that combine human judgment with assisted tools, and fully automated AI-driven labeling. Across all methods, human-in-the-loop (HITL) integration ensures that nuanced or complex labeling tasks are handled with accuracy, providing context-rich datasets for machine learning models.
The outcome of effective data labeling work is clear: AI models trained on high-quality data can recognize patterns, make accurate predictions, and generate actionable insights. This drives operational efficiency, accelerates decision-making, and delivers measurable business impact in real-world applications.
For executives, understanding the data labeling process is essential to ensuring that AI initiatives succeed, scale effectively, and deliver meaningful strategic outcomes.
What are the key data labeling approaches
Data labeling is a strategic capability, and the approach you choose directly affects the accuracy, scalability, and efficiency of your AI initiatives. Selecting the right method requires balancing quality, speed, cost, and the nature of your datasets. Here’s a breakdown of the most widely used approaches and their executive implications.
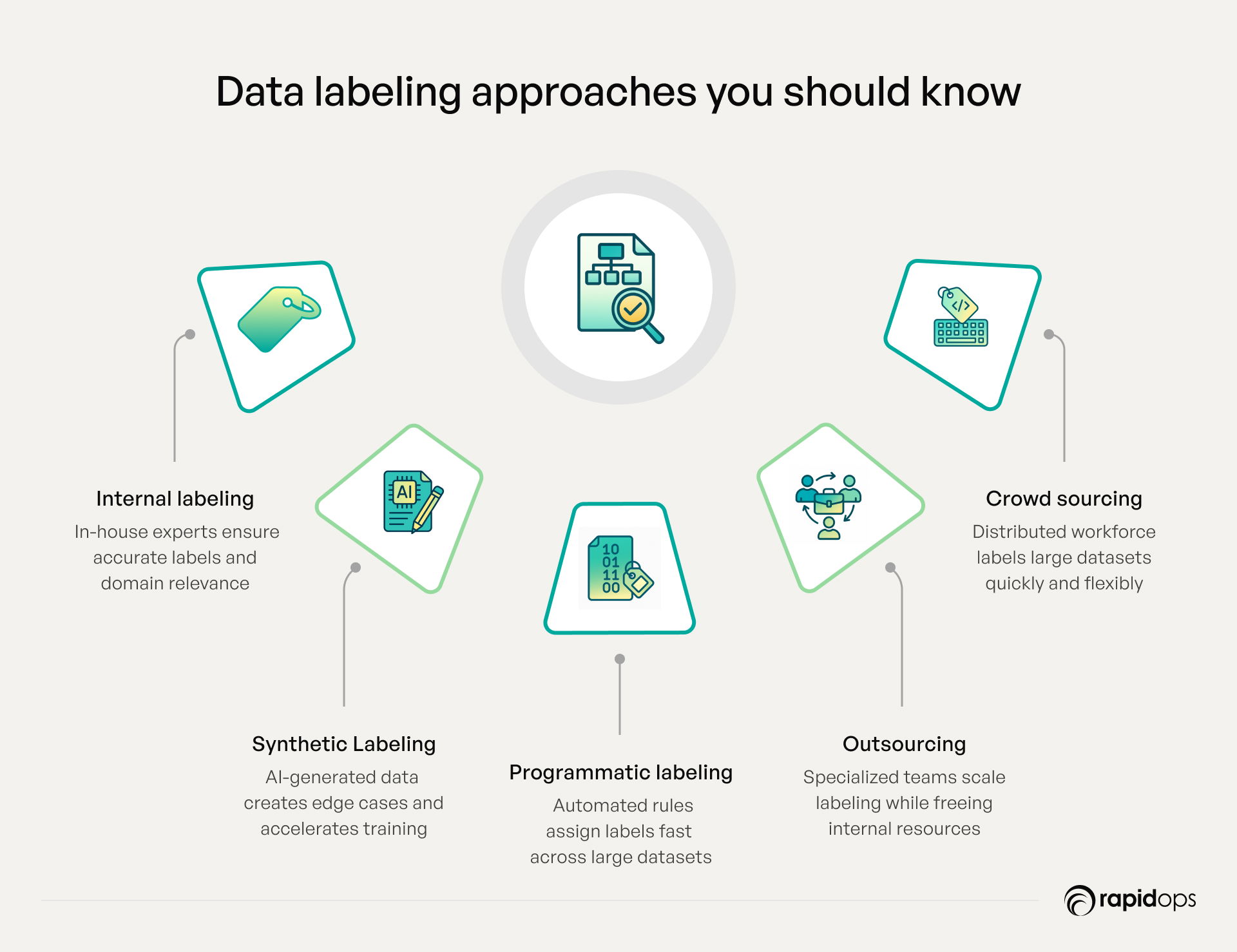
1. Internal labeling
Leveraging in-house experts enables you to apply domain knowledge directly to your datasets, ensuring that labels accurately reflect the business context and operational nuances. Internal labeling allows closer control over quality, enabling iterative feedback and alignment with evolving project requirements. The trade-offs include significant resource allocation, the need for continuous training, and potential scalability challenges for large datasets. For organizations managing highly specialized or sensitive data, this method often provides the highest trust and relevance.
2. Synthetic labeling
Synthetic labeling generates new, labeled data using simulations, AI-generated samples, or augmentation of existing datasets. It helps address data scarcity, create edge cases, and accelerate model training without exhaustive manual effort. While highly efficient, synthetic data must be carefully validated to reflect real-world conditions; poorly simulated datasets can introduce bias or misrepresentations, leading to suboptimal AI predictions. This method is particularly valuable for scenarios like rare events, safety-critical applications, or testing under controlled variations.
3. Programmatic labeling
Programmatic labeling uses automated scripts, AI rules, or prebuilt pipelines to assign labels based on patterns in structured or semi-structured data. This approach excels in speed, scalability, and cost-effectiveness, especially when handling repetitive tasks across large datasets. Executives must ensure robust validation mechanisms are in place, as errors in rules or scripts can propagate quickly and reduce model reliability. Programmatic labeling is ideal for high-volume tasks like categorizing structured data, tagging transactional records, or preprocessing text and numerical datasets.
4. Outsourcing
Outsourcing data labeling to specialized agencies or teams can provide domain-specific expertise and scalability, freeing internal resources for strategic work. This approach enables organizations to tackle large-scale projects quickly while leveraging best practices and established workflows. Critical considerations include data security, compliance with internal standards, and consistent quality checks to maintain reliability across distributed teams. Outsourcing is particularly effective for companies needing rapid ramp-up for projects with high data volumes or specialized technical requirements.
5. Crowdsourcing
Crowdsourcing leverages a distributed workforce via platforms to label large datasets quickly, often bringing diverse perspectives to complex tasks. This method is highly flexible and can scale rapidly, making it suitable for data-intensive domains like NLP, image annotation, or social media analysis. Success depends on well-defined labeling guidelines, multiple annotators per data point to ensure accuracy, and continuous quality audits. Crowdsourcing excels when a broad variety of human judgment is needed to capture subtle or context-specific details.
By understanding and applying the right labeling approaches, whether internal, synthetic, programmatic, outsourced, or crowdsourced, you can ensure your AI models are built on high-quality data that delivers reliable insights, operational efficiency, and measurable business impact.
What are some of the best practices for data labeling
Data labeling is a strategic capability that underpins the performance of AI and machine learning models. Beyond a routine task, it ensures that raw, unstructured information is transformed into high-quality training data, enabling AI to generate reliable predictions, actionable insights, and measurable business outcomes. Following proven best practices allows organizations to optimize accuracy, scalability, and efficiency while reducing errors and operational risks.

1. Intuitive task interfaces
User-friendly labeling platforms simplify workflows, minimize cognitive load, and empower labelers to focus on complex annotation tasks. Platforms that provide visual guidance, contextual cues, and real-time validation enable faster and more precise data labeling, ensuring high-quality datasets across computer vision, NLP, audio, and time-series applications.
2. Labeler consensus for accuracy
Engaging multiple annotators on the same data points mitigates individual bias and ensures consistency. Consensus-based labeling enhances dataset reliability, thereby improving model performance across various deep learning, object detection, sentiment analysis, and recognition tasks. It also helps organizations maintain high-quality labeled data essential for enterprise-grade AI initiatives.
3. Regular auditing and quality checks
Continuous monitoring of annotated datasets ensures integrity as labeling projects scale. Combining automated quality metrics with human review helps detect inconsistencies, correct errors, and maintain accuracy and reliability across diverse data types, including images, video, text, audio, and sensor data.
4. Active learning for efficiency
Active learning leverages AI-driven insights to identify high-impact or ambiguous data points for labeling. Prioritizing these critical points maximizes efficiency, accelerates model training, and enhances predictive performance while minimizing unnecessary labeling effort. This approach ensures that data labeling directly supports faster and more reliable AI deployment.
5. Clear and detailed labeling guidelines
Providing structured instructions, examples, and standards reduces ambiguity and aligns labeling teams. Clear guidelines ensure consistent output across human and automated processes, facilitate scalable workflows, and shorten onboarding for new annotators, while maintaining high-quality data for robust AI model performance.
6. Iterative feedback loops
Incorporating model performance insights into the labeling process enables continuous improvement. Feedback loops reveal areas where labels may be inconsistent or ambiguous, allowing teams to refine datasets over time. This iterative process strengthens AI accuracy, adaptability, and trustworthiness, making data labeling a proactive contributor to business outcomes.
7. Human-in-the-loop (HITL) integration
Combining human expertise with automated labeling ensures that complex, nuanced, or high-stakes data is labeled correctly. HITL strikes a balance between speed, accuracy, and operational efficiency, enabling AI models to handle complex scenarios while maintaining high-quality training data.
8. Scalability and workflow planning
Designing data labeling workflows to accommodate increasing volumes ensures consistent quality and efficiency across enterprise deployments. Scalable processes prevent bottlenecks, reduce operational friction, and support enterprise-wide AI adoption without compromising accuracy or speed.
9. Transfer learning and leveraging prior datasets
Reusing previously labeled datasets or pretrained models accelerates new labeling projects, reduces redundancy, and enhances precision. Transfer learning enables organizations to build upon prior investments, rapidly extend AI coverage to new applications, and maintain high-quality labeled data standards across tasks and domains.
10. Automated and hybrid approaches
Combining human judgment with automated labeling tools further increases efficiency, especially for large-scale datasets. Automation handles repetitive, structured data, while humans validate complex, context-sensitive labels. This hybrid approach ensures speed, accuracy, and reliability in AI model training, supporting a wide range of machine learning use cases.
Applying these practices transforms data labeling from a routine task into a business-critical capability. High-quality, well-managed datasets empower AI to deliver reliable predictions, optimize operations, and generate measurable outcomes that directly support strategic goals.
What are the key industry use cases of data labeling
Computer vision
Labeled visual data enables AI to interpret images and video with precision, supporting tasks such as object detection, image segmentation, and facial recognition. For instance, IBM Maximo Visual Inspection uses annotated images to detect defects on production lines, monitor equipment, and ensure quality control. Accurate labeling reduces manual inspection, accelerates decision-making, and enables predictive analytics, empowering organizations to optimize operations and improve product reliability while maintaining high standards.
Natural language processing (NLP)
Text annotation allows AI to comprehend and analyze language nuances. Labeling for sentiment analysis, entity recognition, intent classification, and machine translation enables chatbots, virtual assistants, and intelligent document processing to provide context-aware responses. Accurate labeling ensures models understand customer queries, extract meaningful insights, and support automated workflows. This drives operational efficiency, enhances customer engagement, and allows organizations to leverage unstructured text into actionable business intelligence.
Retail & eCommerce
Labeled data powers applications like product categorization, visual search, recommendation engines, and inventory optimization. Accurate annotation of product images, descriptions, and user interactions ensures AI models can predict demand, personalize recommendations, and improve search relevance. This drives sales, reduces stockouts, and enhances the customer experience. By prioritizing high-quality labeled data, retailers can optimize operations, tailor offerings at scale, and transform raw customer and product data into a strategic competitive advantage.
Manufacturing & quality control
Data labeling enables AI to detect defects, optimize processes, and predict equipment failures. Annotating images from production lines, IoT sensor readings, or operational logs allows models to identify anomalies, trigger preventive maintenance, and improve process efficiency. High-quality labeling reduces downtime, ensures safety compliance, and enhances production consistency. By systematically labeling operational and sensor data, manufacturers can leverage AI to transform raw information into predictive insights that directly improve performance, reduce costs, and enhance product quality.
What challenges do businesses face in data labeling
While data labeling is crucial to AI success, businesses face numerous challenges that can impact quality, efficiency, and outcomes.
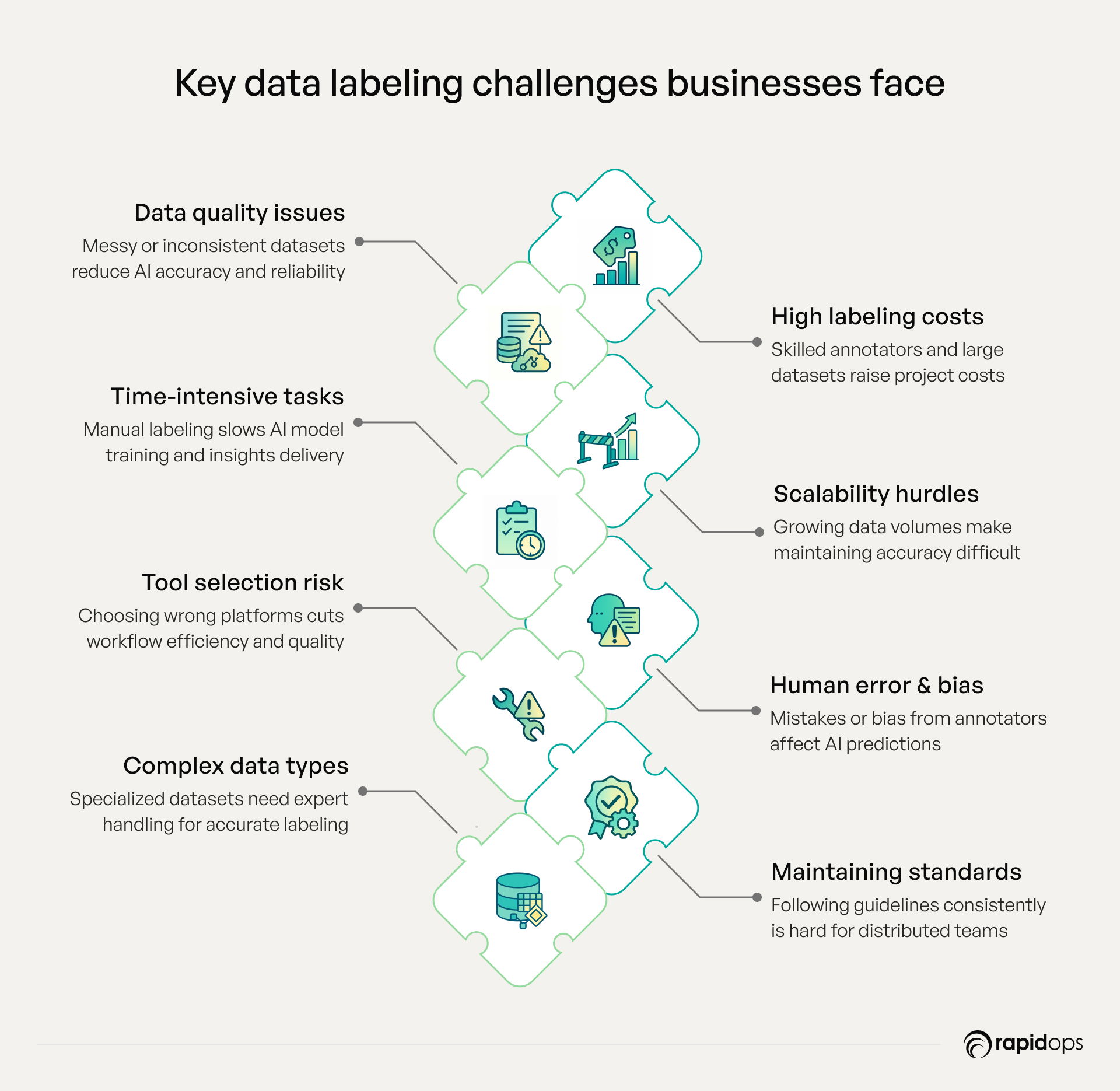
Data quality and consistency
Many organizations struggle with messy, incomplete, or unstructured datasets. Inconsistent labeling or gaps in data can misguide AI models, reducing accuracy and undermining trust in insights.
High costs
Labeling requires balancing budget constraints with the choice between in-house teams or external providers. Skilled human annotators are expensive, and large datasets can quickly escalate costs.
Time-intensive processes
Manual labeling is inherently slow, particularly for high-volume datasets, delaying model training and time-to-insight.
Scalability
As data volumes grow, maintaining accuracy without slowing processes becomes increasingly challenging, requiring careful planning of workflows and tools.
Tool and platform selection
Choosing the right labeling platform or software that supports your data types and workflow is critical. The wrong tools can hinder productivity and compromise quality.
Human error and bias
Even trained labelers can make mistakes or introduce biases, which can impact model fairness, predictions, and overall trustworthiness.
Complex data types
Specialized datasets such as medical images, sensor inputs, or geospatial data require advanced expertise and precise labeling techniques to ensure usable outputs.
Maintaining standards
Ensuring annotators adhere to labeling guidelines consistently is a constant challenge, particularly in distributed or outsourced setups.
Integration with AI/ML pipelines
Labeled data must seamlessly feed into models; gaps or misalignments in integration can slow development or degrade performance.
Adapting to evolving AI needs
As AI models become increasingly complex, labeling processes must also evolve. Updating guidelines, tools, and workflows is necessary to keep pace with changing requirements.
Addressing these challenges strategically, through the right combination of human expertise, automated tools, and scalable processes, ensures labeled data is reliable, high-quality, and capable of driving measurable AI-driven business impact.
Unlock AI’s full potential with strategic data labeling
You’ve explored data labeling, its importance, processes, best practices, and high-impact use cases. One insight is clear: accurate, consistent, and strategically labeled data is not just a technical step; it is the foundation that empowers AI to deliver actionable insights and measurable business outcomes.
We understand the challenges you face. Managing budgets, teams, and complex AI strategies often exposes gaps in underperforming models, slow labeling processes, or costly errors. Thoughtful data labeling addresses these issues by transforming raw, unstructured data into intelligence you can trust, enabling AI to make smarter decisions and drive tangible results.
With 16 years of hands-on experience, Rapidops partners with organizations across retail, manufacturing, and distribution as a specialized AI development company. We design end-to-end AI solutions, encompassing strategy and model development, workflow optimization, and scalable deployment. By ensuring your AI initiatives are built on high-quality, actionable data, we accelerate decision-making, reduce operational inefficiencies, and maximize measurable business impact.
Take the next step: Schedule an appointment with one of our AI specialists for a complimentary consultation and transform the insights you’ve explored here into faster, smarter, and more reliable AI outcomes.

What’s Inside
- What is data labeling
- Why data labeling is essential for businesses
- Types of data labeling
- How does data labeling work
- What are the key data labeling approaches
- What are some of the best practices for data labeling
- What are the key industry use cases of data labeling
- What challenges do businesses face in data labeling
- Unlock AI’s full potential with strategic data labeling

Let’s build the next big thing!
Share your ideas and vision with us to explore your digital opportunities
Similar Stories
- AI
- 4 Mins
- September 2022


- AI
- 9 Mins
- January 2023

Receive articles like this in your mailbox
Sign up to get weekly insights & inspiration in your inbox.