

Every day, leaders like you face relentless pressure to innovate with AI, to unlock fresh insights, accelerate growth, and stay ahead in a world where technology evolves at lightning speed. Yet beneath this AI revolution lies a persistent challenge: the data gap.
Many enterprises grapple with AI models faltering due to insufficient, non-diverse, or restricted data driven by evolving privacy regulations. Paradoxically, even as data volumes explode, accessing reliable, comprehensive, and ethical data remains a critical struggle. These obstacles extend beyond technology, they create strategic bottlenecks that stall your vision and limit ROI.
Imagine trying to teach a language with an incomplete vocabulary or paint a masterpiece without a full palette. Building AI without quality data is just as frustrating. Traditional datasets often suffer from gaps, bias, and fragmentation, while regulatory complexities grow ever more demanding. The essential question is no longer how to build AI, but how to make AI that truly works, respects privacy, and delivers measurable business value.
Synthetic data generation is a strategic breakthrough that creates accurate, artificial data to bridge gaps and protect privacy. In retail, it drives personalization and dynamic pricing; in manufacturing, it enables predictive maintenance; and in distribution, it improves demand forecasting and route optimization, boosting efficiency and resilience.
As you read on, discover what synthetic data generation means, why it’s crucial now, and how it can unlock new pathways to business innovation in your industry.
What is synthetic data generation?
Synthetic data generation creates artificial data that closely mimics real data, addressing privacy and scarcity challenges. Understanding its definition, differences, and types is key to leveraging its full potential.
Definition of synthetic data and synthetic data generation
Synthetic data is artificially generated information designed to accurately replicate the statistical properties, patterns, and relationships present in real-world datasets without containing any actual personal or sensitive information. Unlike anonymized or masked data, synthetic data is fully fabricated, eliminating any risk of exposing confidential details. This makes it a critical resource for organizations operating under strict privacy regulations such as GDPR and HIPAA, enabling them to derive rich insights while maintaining full compliance.
Synthetic data generation is the advanced computational process of creating artificial datasets using techniques such as generative models, simulations, and machine learning algorithms. These methods produce data that closely mirror the distribution and complexity of authentic data, addressing key challenges such as data scarcity, sampling bias, and regulatory constraints.
It is crucial to understand that a significant number of AI initiatives fail or fall short not because of flawed models, but due to insufficient or poor-quality data. Many enterprises lack access to the volume, variety, or diversity of data necessary to train effective AI systems. Privacy concerns and legal restrictions further limit the availability of usable datasets, severely constraining AI potential.
Synthetic data generation transforms this landscape by enabling enterprises to generate customized, scalable, and privacy-compliant data tailored to their specific business contexts. This empowers organizations across industries to overcome traditional data limitations, accelerate AI adoption, improve model robustness, and reduce time-to-market for innovative, data-driven analytics solutions. Ultimately, synthetic data serves as the foundational enabler that turns AI from a constrained experiment into a reliable driver of sustained business value.
Understanding how synthetic data differs and exploring its main types
For senior business leaders navigating the complexities of data-driven innovation, grasping how synthetic data fundamentally differs from real and anonymized data is crucial for informed generative AI strategy consulting.
Synthetic data is distinct because it is artificially generated rather than collected from real-world events or individuals. Unlike real data, which contains authentic records but often raises privacy and regulatory challenges, synthetic data offers a privacy-first alternative that replicates the statistical properties of actual datasets without exposing sensitive information. This distinction positions synthetic data as a transformative enabler for enterprises seeking scalable, compliant, and bias-mitigated data solutions.
Further differentiation lies in its relationship to anonymized data. While anonymized data modifies real data by removing or masking personally identifiable information (PII), it remains rooted in actual records and can sometimes be vulnerable to re-identification risks. Synthetic data, by contrast, is generated anew, ensuring no direct connection to original individuals, thereby providing stronger privacy safeguards.
Synthetic data comes in three primary types, each serving unique business needs.

- Fully synthetic data: Entirely artificial datasets generated without any real data input, ideal for situations demanding maximum privacy and compliance.
- Partially synthetic data: Real datasets supplemented by synthetic elements, used to augment data volume or address gaps while preserving overall data integrity.
- Hybrid synthetic data: Combines real and synthetic data in a balanced manner to optimize both authenticity and privacy, supporting advanced AI model training and testing.
Understanding these distinctions and types empowers decision-makers to select the right synthetic data approach aligned with their organizational goals, regulatory requirements, and AI initiatives, unlocking innovation while safeguarding trust and compliance.
Why is there a need for synthetic data generation
Real-world data often falls short due to privacy laws, incompleteness, or bias, stifling AI innovation and reliable decision-making. Synthetic data generation directly solves these issues by providing rich, safe, and customizable datasets that empower businesses to build smarter, fairer, and faster AI solutions without compromising compliance or quality.

1. Data scarcity and incompleteness
Businesses often struggle with the absence of sufficient, complete, or representative real-world data necessary for effective AI and analytics. Many industries face challenges in gathering comprehensive datasets, which impedes their ability to build accurate predictive models. Synthetic data bridges this gap by providing high-quality, simulated data.
2. Expensive and difficult data collection
Collecting, labeling, and maintaining high-quality real-world data is both time-consuming and costly. Traditional data collection methods pose significant logistical challenges, including obtaining permissions and ensuring data integrity. Synthetic data alleviates these concerns by providing an affordable, efficient way to generate diverse datasets at scale.
3. Limitations of traditional anonymization
Anonymized data, while designed to protect privacy, still carries risks of re-identification due to subtle patterns that can be traced back to individuals. Synthetic data provides a safer alternative by generating entirely artificial datasets that retain statistical properties of real data without the possibility of identifying individuals.
4. Reducing data bias and imbalances
Real data often contains inherent biases or underrepresentation of certain groups, events, or conditions, which can skew AI model outcomes. Synthetic data enables businesses to create balanced datasets that ensure diverse, unbiased representation, leading to more accurate, fair, and ethical AI models that are better aligned with real-world scenarios.
5. Enabling innovation and rapid experimentation
Synthetic data accelerates innovation by offering businesses the freedom to test and validate AI models, software systems, and products without the limitations and risks associated with real data. This promotes faster experimentation and iteration, driving progress while maintaining the integrity and security of proprietary information.
6. Training robust AI models
Synthetic data plays a crucial role in training AI models, especially for rare or hard-to-capture events and scenarios. By augmenting real data with synthetic datasets, businesses can ensure their AI systems are more robust, resilient, and capable of generalizing across a broader range of conditions, ultimately improving model performance.
7. Ensuring business continuity and risk mitigation
Synthetic data supports business continuity by allowing organizations to share and collaborate internally and externally without exposing sensitive information. By using simulated data for testing, training, and development, businesses can mitigate the risks associated with data breaches and privacy violations, ensuring secure operations.
8. Overcoming industry-specific challenges
In industries like finance and retail, limited access to real data often hinders AI adoption and innovation. Synthetic data provides industry-specific solutions by simulating sensitive or rare events, ensuring that AI models are trained with diverse and representative data while overcoming regulatory and privacy challenges unique to each sector.
9. Cost efficiency and scalability
Generating synthetic data offers a highly cost-effective and scalable solution compared to the ongoing expense of collecting and curating real-world datasets. By automating data generation, businesses can rapidly produce large volumes of high-quality data, enabling generative AI development at scale without incurring significant operational costs.
How is synthetic data generated
Synthetic data generation is a sophisticated, strategic process that transforms how businesses access and leverage data for AI, analytics, and innovation.
At its core, synthetic data generation uses advanced techniques to create artificial datasets that closely mirror the statistical properties and patterns of real-world data, without exposing sensitive information. This enables enterprises to overcome pivotal challenges such as data scarcity, privacy constraints, and the cost of data collection.
Several key methodologies define the generation process.
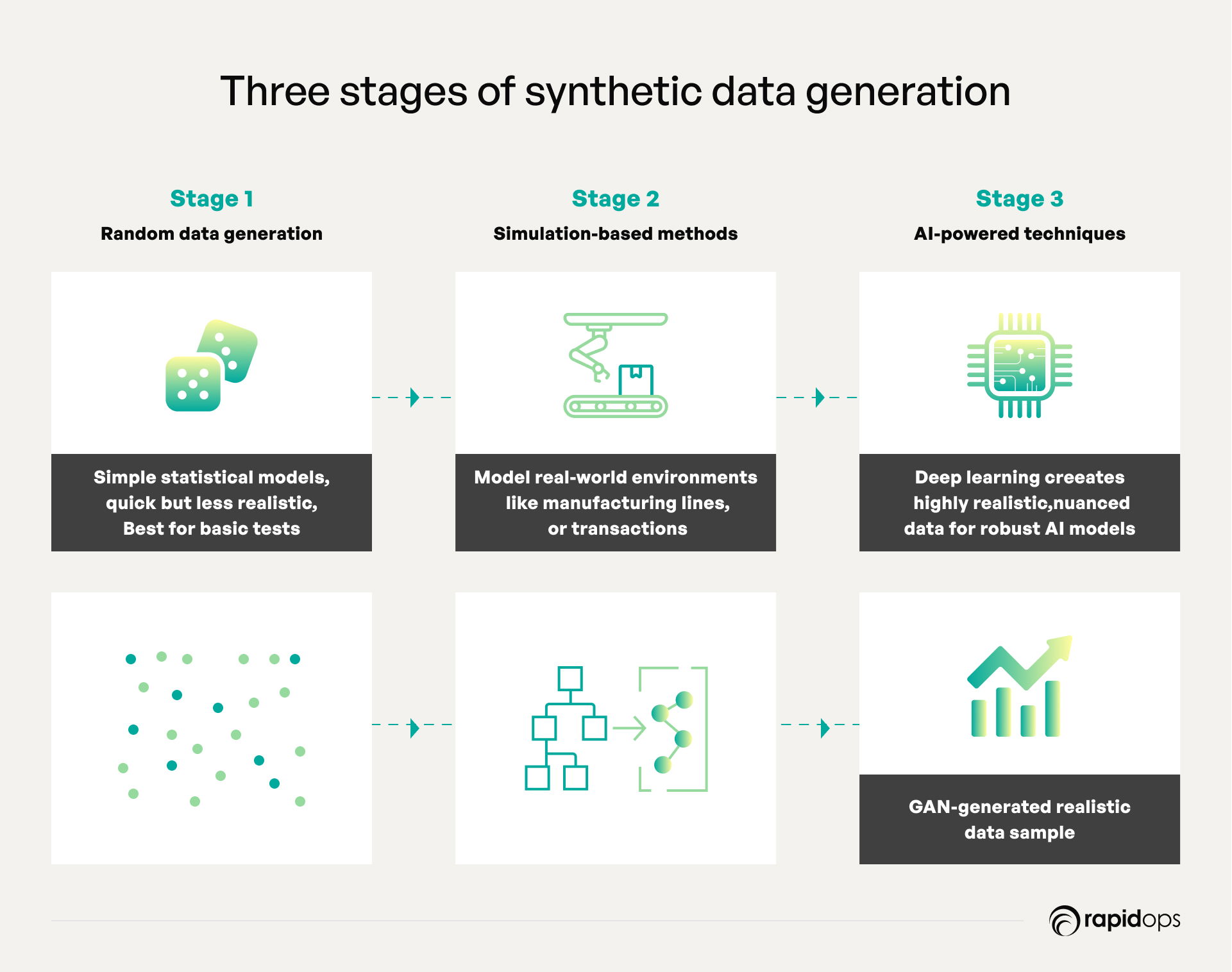
- Random data generation: The foundational approach involves generating data points based on statistical models or random sampling. While simple and efficient for basic scenarios, this method lacks nuanced realism and is best suited for preliminary tests or straightforward simulations.
- Simulation-based methods: These techniques build virtual models of real-life environments or processes, such as customer journeys, financial transactions, or manufacturing workflows. By simulating complex interactions and behaviors, businesses obtain contextual synthetic data that faithfully replicates real-world dynamics critical for system testing and scenario analysis.
- AI-powered techniques (GANs and VAEs): The frontier of synthetic data generation leverages deep learning models such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). These systems learn intricate relationships and high-dimensional data distributions from original datasets, then create highly realistic synthetic counterparts. This approach ensures generated data captures subtle patterns and variability necessary for training robust, unbiased AI models.
Effective synthetic data generation relies on clean, high-quality input data and rigorous validation to ensure synthetic datasets maintain statistical fidelity and usefulness. Leading platforms such as Synthea, Hazy, and MOSTLY AI streamline this process, offering scalable, customizable synthetic data solutions tailored to industry-specific needs, whether in finance, retail, or beyond.
For business leaders, synthetic data generation accelerates AI, ensures privacy, reduces risk, and drives innovation, turning data into a reliable, ethical, competitive advantage.
Best practices for using synthetic data in business
Think of synthetic data as your enterprise’s innovation sandbox, safe, scalable, and full of possibilities. It can help you train AI systems faster, explore scenarios you can’t test in the real world, and work around strict data regulations. But the real magic happens when you use it the right way. Following best practices ensures you turn potential into performance.

1. Start with clean, high-quality original data
The foundation of effective synthetic data generation lies in the quality of the original data. Businesses must ensure that their real datasets are accurate, complete, and properly cleaned. High-quality input data ensures that synthetic datasets reflect real-world complexities, allowing AI models to perform optimally. This initial data hygiene reduces bias, errors, and inconsistencies, maximizing the potential of artificial data.
2. Test the quality of synthetic data rigorously
Businesses should continuously validate synthetic data to ensure it replicates the statistical properties and variability of real-world data. Statistical tests and performance evaluations should be conducted to compare synthetic datasets against real data, ensuring their reliability for training AI models. This practice ensures that synthetic data supports robust decision-making and does not undermine model performance.
3. Balance synthetic and real-world data
While synthetic data is valuable for overcoming data scarcity, combining it with real-world data can enhance model performance. Synthetic data should augment real data, filling in gaps while retaining critical nuances. This blended approach ensures a comprehensive training set, leading to better generalization and more accurate predictions in AI models, especially for rare or hard-to-capture events.
4. Leverage privacy-preserving techniques
Despite synthetic data's advantages, businesses should still implement privacy-preserving techniques, such as differential privacy, to ensure that no unintended patterns from real-world data are carried over. By adding noise or obfuscating specific details, businesses can further safeguard sensitive information, ensuring compliance with privacy regulations like GDPR and HIPAA while innovating securely.
5. Choose the right tools and technologies
Selecting the appropriate synthetic data generation tools is crucial to ensuring the quality, scalability, and relevance of generated datasets. Businesses should evaluate platforms based on their specific industry needs, data types, and objectives. Choosing the right toolset helps ensure that synthetic data can be seamlessly integrated into the business's existing data infrastructure for optimal impact.
6. Collaborate with domain experts
Synthetic data generation should not be left solely to data scientists. Collaboration with domain experts is vital to ensure that generated data aligns with industry-specific needs and real-world scenarios. Involving professionals with firsthand knowledge ensures that synthetic data accurately reflects the nuances of each sector, from finance to healthcare, making it more relevant for training and decision-making.
7. Start small with pilot projects
Businesses should begin with small-scale synthetic data initiatives to assess their value before scaling. Pilot projects allow teams to evaluate the quality and performance of synthetic data in real-world scenarios without committing significant resources. This iterative approach helps businesses fine-tune their synthetic data strategy, minimizing risk while maximizing ROI.
8. Monitor data quality and performance continuously.
The effectiveness of synthetic data depends on regular monitoring and optimization. Businesses should continuously track the performance of AI models trained on synthetic data, ensuring they evolve with changing data trends and business needs. This ongoing evaluation process helps identify areas for improvement, ensuring long-term effectiveness.
9. Use synthetic data for safe innovation and experimentation
One of the key advantages of synthetic data is its ability to facilitate experimentation and innovation without exposing sensitive real-world data. By leveraging synthetic data for testing new features, systems, and models, businesses can explore new technologies, refine strategies, and gain insights without compromising security, privacy, or compliance.
10. Ensure cross-industry adaptability
Different industries have unique challenges and requirements when it comes to synthetic data. Businesses should tailor their synthetic data approach to their specific industry, whether finance or retail, ensuring the data reflects relevant scenarios. By customizing synthetic data generation for each sector, companies can unlock industry-specific insights, enhancing their competitive edge and fostering innovation.
By following these best practices, businesses unlock synthetic data's full potential, accelerate AI innovation, ensure privacy compliance, and improve decision-making. Integrating these strategies keeps organizations ahead, driving growth while safeguarding data and operations.
High-impact synthetic data generation use cases
Synthetic data has moved from a niche innovation to a strategic enabler for enterprises navigating AI adoption at scale. For leaders in retail, manufacturing, and distribution, it offers a way to accelerate model development, reduce operational risk, and ensure compliance without sacrificing data quality or diversity. Below are the most relevant use cases for 2025, beginning with the foundational AI/ML enabler and moving into high-impact, industry-specific applications.
1. Dynamic pricing optimization with synthetic data
Traditional pricing models rely on limited historical data, often missing sudden competitor price changes, regional demand surges, and promotional impacts. This limits pricing agility and revenue potential. Synthetic data generation addresses these gaps by creating detailed, realistic scenarios, including competitor discount campaigns and localized demand shifts that AI pricing engines use to train and adapt. For example, when a competitor launches an unexpected promotion, synthetic data enables AI models to simulate pricing responses in real time, allowing businesses to adjust prices accordingly. This leads to optimized margins, faster decisions, increased sales velocity, and sustained competitiveness for retail, manufacturing, and distribution leaders. Integrating synthetic data transforms pricing into a proactive, data-driven strategy that fuels growth and resilience.
2. Computer-vision training for stores, warehouses, and factories
Synthetic imagery is transforming how enterprises train computer-vision models, eliminating the dependency on costly, time-consuming, and incomplete real-world datasets. Retailers can simulate rare in-store scenarios like theft under low light or misplaced items to improve loss prevention and planogram compliance. Manufacturers can replicate subtle defect variations under different lighting and camera angles for quality inspection. Distribution centers can model cluttered aisles, occlusions, and rapid object movement for robotics navigation. By covering edge cases and environmental variability, synthetic datasets ensure vision systems perform reliably in live operations.
3. Digital twins and predictive maintenance
Digital twins gain unprecedented realism when enriched with synthetic sensor data that captures both typical performance and rare failure modes. Manufacturers can model thermal spikes, bearing degradation, or multi-component system failures without halting production. Distribution operations can simulate conveyor overloads, sorting inaccuracies, and environmental stresses. These datasets train predictive-maintenance models to anticipate and address problems before they occur, enabling reduced downtime, optimized maintenance schedules, and safer operations, all without the cost and risk of physical failure testing.
4. Demand forecasting and supply-chain stress testing
Synthetic time-series datasets allow enterprises to pressure-test forecasting models and supply-chain policies under extreme conditions. Retailers can simulate unprecedented sales spikes from promotions or sudden market shifts. Manufacturers can model supplier delays or raw material shortages, while distributors can replicate port closures, transport disruptions, or weather-related delays. This controlled scenario modeling helps leaders evaluate contingency strategies, optimize inventory, and strengthen resilience against real-world shocks, protecting service levels and margins during volatility.
5. Privacy-preserving data sharing and collaborative analytics
Privacy-enhanced synthetic datasets enable secure collaboration between retailers, manufacturers, logistics partners, and analytics vendors without exposing personally identifiable information (PII). By retaining statistical utility while eliminating re-identification risk, these datasets unlock cross-organizational benchmarking, vendor evaluation, and joint innovation. Retailers can share customer behavior trends, manufacturers can compare supplier efficiency, and distributors can exchange operational insights, all while meeting compliance mandates. This approach accelerates partnership-driven value creation without compromising trust or regulatory standing.
6. Automated QA, testing, and resilient MLOps
Synthetic datasets are becoming a vital asset in enterprise QA and MLOps pipelines. Retail platforms can simulate checkout and payment flows under peak loads with realistic but non-sensitive transaction data. Manufacturing systems can generate synthetic sensor alerts to validate monitoring dashboards. Distribution platforms can replicate delivery anomalies or GPS dropouts for routing algorithms. Embedding synthetic data into CI/CD workflows improves release quality, expands edge-case coverage, and reduces production incidents, turning testing from a reactive bottleneck into a proactive enabler of operational reliability.
7. Personalization and recommender-system robustness
Synthetic user profiles and interaction histories allow safe experimentation on personalization models without risking exposure of real customer data. Retailers can model diverse shopping journeys, from new visitors to loyal customers, including rare or unexpected behaviors. Manufacturing marketplaces can replicate unique buyer requirements, while distributors can model B2B accounts with seasonal or fluctuating order volumes. These synthetic datasets enable teams to detect and address bias, improve cold-start performance, and ensure inclusive personalization strategies that engage all customer segments effectively.
8. Product design, generative R&D, and virtual prototyping
Synthetic usage data and simulated product interactions are reshaping design and innovation cycles. Retailers can predict durability issues or return rates for apparel and electronics before physical prototyping. Manufacturers can model product performance under extreme conditions to inform engineering decisions. Distributors can evaluate packaging resilience and handling efficiency across transportation modes. By integrating synthetic data into generative design workflows, organizations shorten development cycles, reduce prototype costs, and prioritize market-ready innovations with higher success potential.
Understanding the challenges and limitations of synthetic data
Grasping the challenges and limitations of synthetic data is crucial for leaders who want AI to deliver real, trustworthy value. By facing realities like imperfect data fidelity, hidden biases, complex regulations, and integration hurdles head-on, decision-makers can safeguard their investments and unlock AI’s full potential to transform their business responsibly and sustainably.

1. Data quality and realism
Synthetic data often struggles to fully replicate the nuanced complexity, diversity, and rare edge cases of real-world datasets. This gap can result in AI models that perform well in test environments but falter in real applications, limiting accuracy, robustness, and reliability. Ensuring the fidelity of synthetic data remains a key technical challenge for enterprise adoption.
2. Bias and fairness risks
Synthetic data can inherit or even magnify biases present in source datasets or the generation process itself. Without scrutiny, this perpetuation of bias risks producing unfair or unethical AI decisiofns, which can damage brand reputation and violate compliance mandates, particularly critical in sectors like finance, healthcare, and retail.
3. Regulatory and privacy ambiguity
Although synthetic data aims to protect individual privacy, global regulations lack a clear consensus on its legal status. Uncertainty around data anonymization standards, re-identification risks, and audit requirements creates compliance challenges for enterprises seeking to leverage synthetic data without inadvertently breaching privacy laws.
4. Integration complexity
Integrating synthetic data workflows into existing enterprise data architectures is complex. Challenges include aligning with diverse data sources, ensuring compatibility with analytics and MLOps tools, maintaining data lineage, and managing operational overhead, which requires robust engineering to avoid disruptions and enable seamless AI lifecycle management.
5. Scalability constraints
Scaling synthetic data generation for large, enterprise-grade datasets demands high computational resources and optimized processes. Insufficient infrastructure or inefficient workflows can delay data availability, slow AI model training, and increase costs, impacting an organization’s ability to iterate and respond to market changes rapidly.
6. Expertise deficit
Effective synthetic data creation requires specialized expertise spanning data science, domain knowledge, privacy engineering, and ethical oversight. The scarcity of such cross-functional skills within many organizations limits their ability to generate quality data that meets both business goals and regulatory standards, hindering AI innovation.
7. Intellectual property and data ownership
The emergence of synthetic data raises complex questions about ownership rights. Enterprises must navigate ambiguous legal territory concerning who controls synthetic datasets, especially when generated from proprietary, licensed, or third-party data. These uncertainties can stall adoption due to risks around data usage, sharing, and monetization.
Future trends in synthetic data generation
As synthetic data matures into a foundational pillar of enterprise AI, its evolution over the next decade will be shaped by transformative trends that redefine data creation, privacy, and intelligence. By 2030, forward-looking organizations must anticipate these shifts to strategically leverage synthetic data for competitive advantage.
1. Hyper-realistic synthetic data through advanced generative models
Next-generation generative architectures, beyond today’s GANs and diffusion models, will create synthetic datasets indistinguishable from real-world data, capturing subtle complexities and rare edge cases. This leap will enable AI systems to train with unparalleled accuracy and robustness, minimizing performance gaps between simulated and real environments.
2. Fully automated synthetic data pipelines integrated into AI lifecycle
Synthetic data generation will become seamlessly embedded within end-to-end MLOps platforms, enabling continuous, dynamic data creation aligned with evolving model requirements. This integration will empower enterprises to accelerate AI training, testing, and deployment cycles while maintaining strict governance and compliance.
3. Privacy-first synthetic data with provable guarantees
Emerging cryptographic techniques and differential privacy advances will provide mathematical guarantees that synthetic data cannot be traced back to individuals. This will unlock new levels of trust, compliance, and data sharing across sectors constrained by stringent privacy regulations.
4. Multi-modal synthetic data generation
By 2030, synthetic data will extend beyond structured tabular formats to encompass complex multi-modal data combining text, images, video, sensor inputs, and IoT streams. This convergence will power richer, context-aware AI applications across industries like manufacturing, retail, and logistics.
5. Adaptive synthetic data that evolves with AI models
Synthetic datasets will continuously evolve in response to model performance metrics, closing feedback loops between AI systems and data generation processes. This adaptive approach will ensure sustained model relevance and resilience in dynamic operational environments.
6. Democratization of synthetic data tools with low-code/no-code platforms
Innovations in user-friendly synthetic data platforms will empower non-technical business leaders and domain experts to generate high-quality synthetic datasets without deep AI expertise. This shift will drive broader synthetic data adoption and unlock innovation across enterprise functions.
7. Synthetic data as a service (SDaaS) ecosystems
By 2030, synthetic data generation will increasingly be delivered as scalable cloud services integrated with enterprise data ecosystems. SDaaS will offer on-demand, customizable synthetic datasets tailored to specific industry, regulatory, and operational needs, enabling agility and cost efficiency.
Turning synthetic data from concept to competitive advantage
You’ve seen how synthetic data generation can redefine business innovation, yet the path to adoption is often filled with important questions about accuracy, privacy, and seamless integration into complex operations. These challenges are not just theoretical; they’re real-world obstacles that organizations in retail, manufacturing, and distribution face every day.
At Rapidops, we bring proven, industry-specific experience to these challenges. From empowering retailers to refine personalized customer experiences through AI models, to helping manufacturers predict equipment failures before they happen, and enabling distributors to optimize supply chains with greater precision, we’ve crafted solutions that deliver measurable impact. Our expertise ensures that synthetic data doesn’t just remain a concept but becomes a strategic asset tailored to your business realities.
Interested in discovering how synthetic data can help your business? Schedule an appointment with one of our synthetic data experts. Our expert will guide you through easy ways to protect your data, spark innovation, and grow your business.
Frequently Asked Questions

What’s Inside
- What is synthetic data generation?
- Why is there a need for synthetic data generation
- How is synthetic data generated
- Best practices for using synthetic data in business
- High-impact synthetic data generation use cases
- Understanding the challenges and limitations of synthetic data
- Future trends in synthetic data generation
- Turning synthetic data from concept to competitive advantage

Let’s build the next big thing!
Share your ideas and vision with us to explore your digital opportunities
Similar Stories
- AI
- 4 Mins
- September 2022


- AI
- 9 Mins
- January 2023

Receive articles like this in your mailbox
Sign up to get weekly insights & inspiration in your inbox.